
Open API
끝말잇기에서 사용할 명사 리스트를 모으기 위해서는 한글 단어 사전의 API 가 필요했다. 그 중에서도 한글표준어대사전 과 우리말샘 이라는 두 가지 선택지가 있었다. 처음에는 한글표준어대사전을 선택하였으나 우리말샘 API 가 단어의 유형을 조금 더 상세히 표현한다는 것을 깨닫고 우리말샘으로 넘어가게 되었다.
API 이용신청은 신청 즉시 승인되는 방식이어서 따로 시간이 들지 않았다.
XML 파싱

제공되는 Open API 는 위 사진과 같이 xml 형태여서 xml parsing 작업이 필요했다. 우선 이 API 를 간단히 활용하며 테스트 하기 위해 간단한 proto-type을 만들어보기로 했는데 역시 이런 작업에는 python 의 beautifulsoup 만한 게 없었다.

사실 python 을 직접 활용해 본 경험은 ps 나 코딩테스트에서 C++ 로 풀기 난해한 string 처리 문제를 풀어볼 때 밖에 없었고 다양한 라이브러리의 기능들만 어느정도 아는 수준이었는데 이번 기회를 통해 python 과 더욱 친숙해질 수 있을 것 같았다.
단어 유효성 검사
우선 끝말잇기에서 사용 가능한 단어의 규칙은 다음과 같았다.
- 명사만 허용된다.
- 표준어만 허용된다.
- 북한어/외국어는 허용되지 않는다.
- 합성어는 허용되지 않는다.
- 고유명사는 허용되지 않는다.
- 단어의 길이가 2 이상이어야 한다.
이 외에도 더 있을 수 있겠지만 우선 proto-type 에서 사용한 규칙은 이 정도이다.
아래는 API 와 python 을 이용해 간단히 작성한 단어 유효성 검사 코드이다.
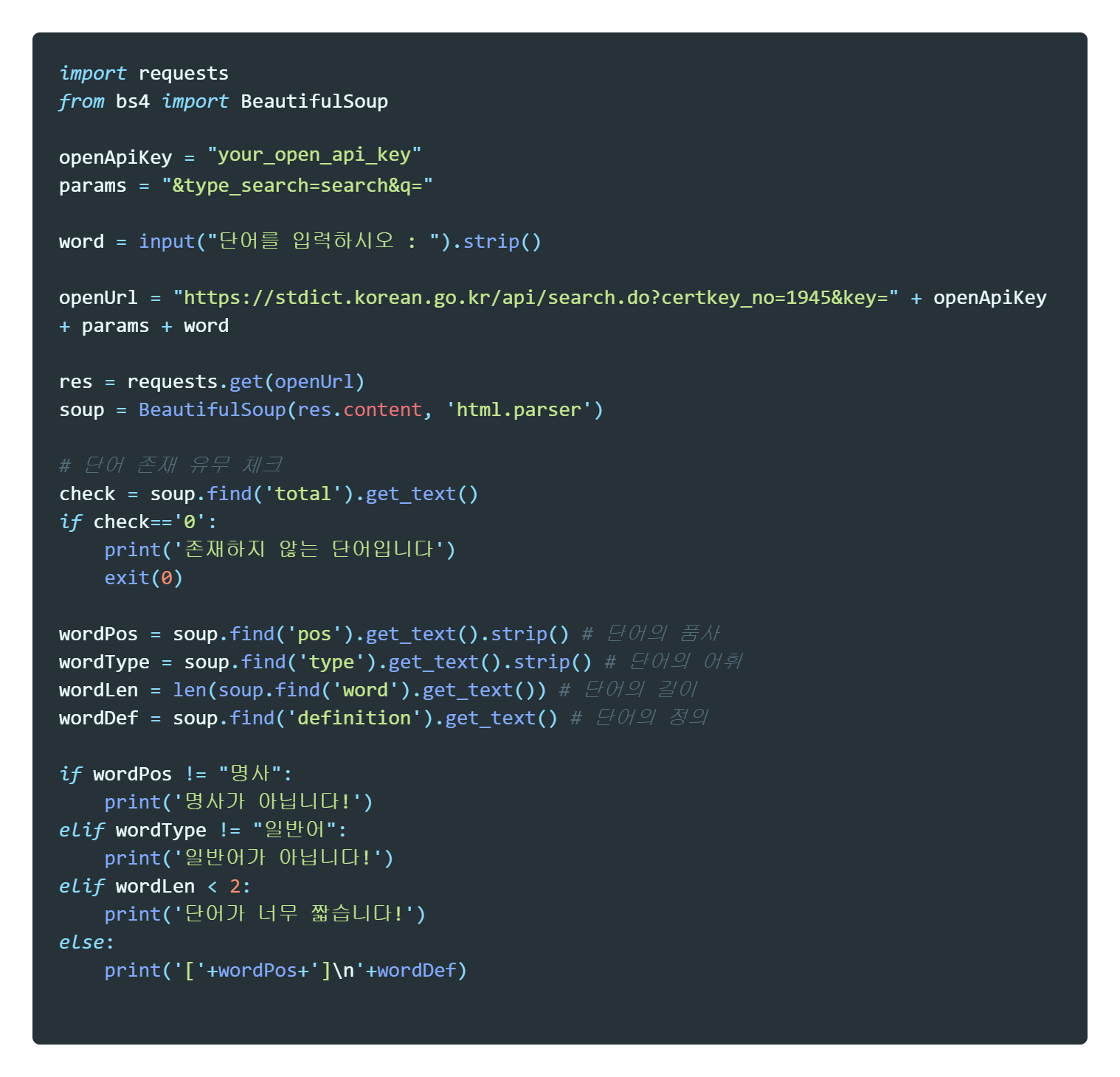
사용자가 입력한 단어는 위 코드를 통해 올바른 단어인지 판별할 수 있다.
그렇다면 AI 가 답할 단어는 어떻게 생성해내야 할까?
단어 리스트 생성
이 프로젝트의 AI 는 임의의 단어를 만들어낼 만큼의 고수준 AI 가 아니기 때문에 사전에 미리 단어 리스트를 만들어 주어야 한다. 위 API 에서는 단어를 통한 검색 뿐만 아니라 각 단어에 부여된 target-code 을 이용한 검색 또한 지원하기 때문에 1번 부터 끝까지 모든 target-code 를 참조하여 사전 API 내의 모든 단어를 탐색할 수 있었다. 이 단어들 중에서 위에서 만든 단어 유효성 검사를 통과한 단어만 리스트에 넣어주고 AI 는 이 리스트에서 사용자가 입력한 단어의 끝말로 시작하는 단어를 탐색하여 출력하면 될 것이다.
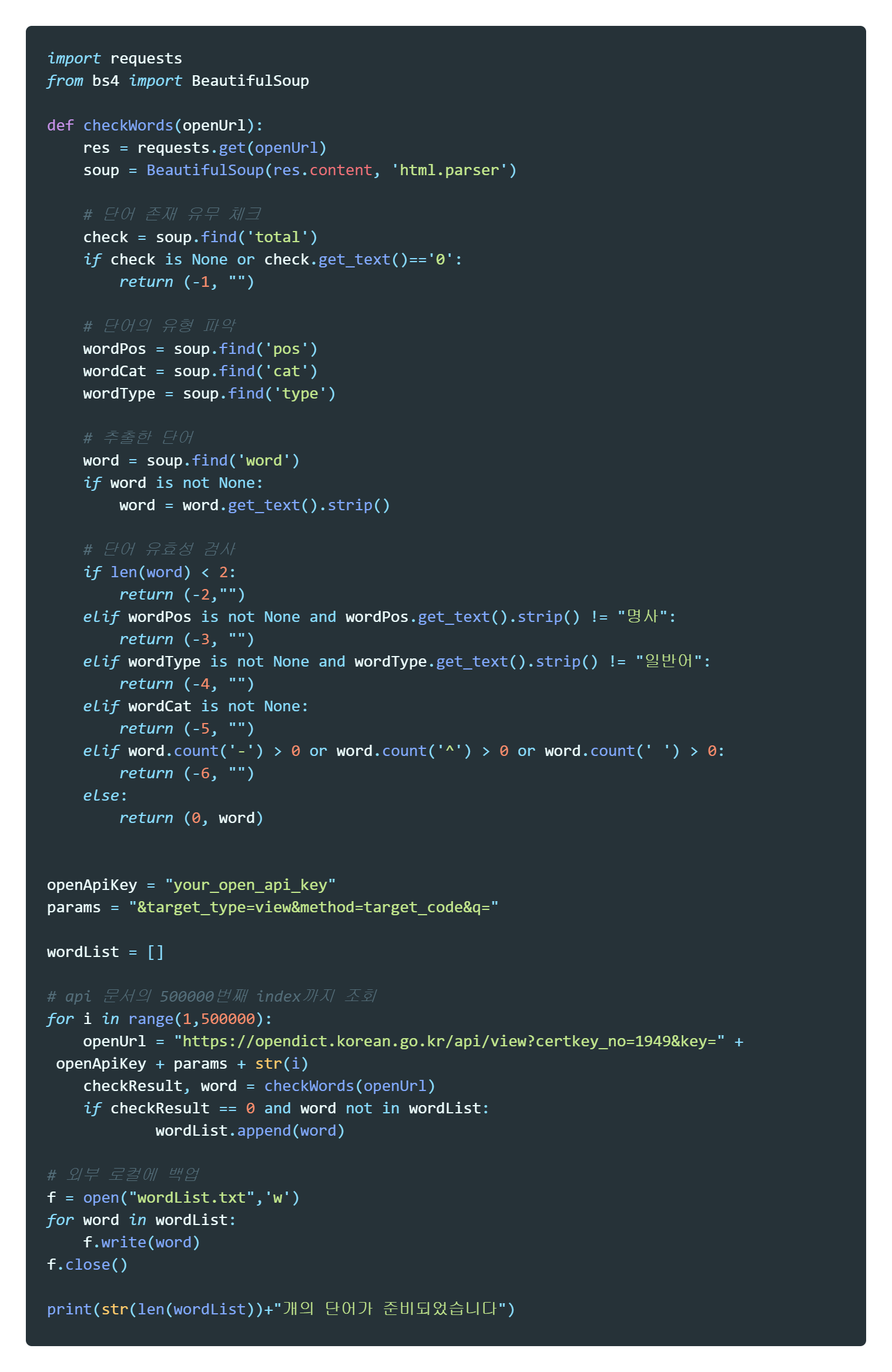
API 에서 target-code 는 약 500000번 까지 있었다. 이 모든 인덱스를 탐색하는 데에는 상당히 오랜시간이 걸렸다.
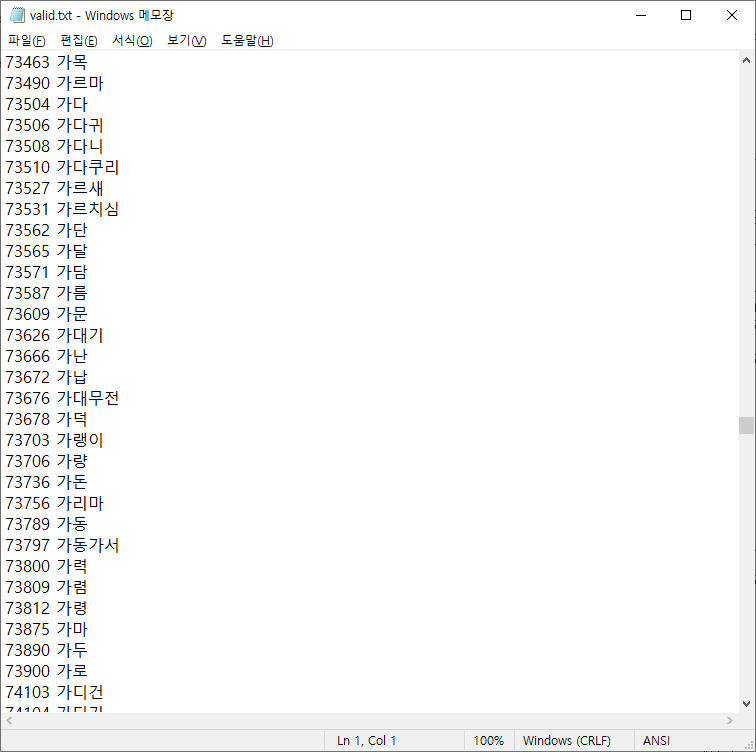
어쨌든 무사히 추출 성공!
- Post link: https://blog.yjyoon.dev/project/2020/10/11/enphago-02/
- Copyright Notice: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.